SkipManager: Skip everything in the RL pipeline.
Last updated: 2026-07-08
1. Overview
SkipManager (verl.utils.skip.SkipManager) is a general-purpose framework for skipping
selected steps in verl training flows. By bypassing expensive stages on configured steps, it helps
save time, memory, or other resources and improves developer iteration speed during
debugging and experimentation.
Skip behavior is centralized under the top-level Hydra key skip. Modules register by role
(for example "rollout", "rollout_tq", or "async_rollout") and are attached with
@SkipManager.annotate(role=…) (or @SkipManager.annotate_tq(role=..., phase=...) for the
V1 two-phase path). Each role declares which integer steps in config are eligible for skip
logic. Today only rollout-related roles are implemented; the same mechanism can be extended to
other pipeline stages (see section 6).
Typical use cases
SkipManager is intended for development workflows where repeating full training is costly:
Faster iteration: skip heavy stages on chosen steps (e.g. generation) while exercising the rest of the pipeline.
Deterministic replay: cache and reload intermediate results to reproduce a prior run on specific steps.
Resource savings: avoid recomputing or holding large tensors when bisecting bugs or tuning downstream logic.
The built-in rollout / rollout_tq / async_rollout modules apply this to sequence
generation; other roles can follow the same pattern as they are added.
Supported entry points today
Training entry |
Skip role / config |
Status |
|---|---|---|
|
|
Supported |
main_ppo.py with trainer.use_v1=True (V1 PPOTrainer + TransferQueue) |
``skip.rollout_tq |
Supported (see section 4) |
|
|
Supported |
2. Configuration (skip.rollout / skip.rollout_tq / skip.async_rollout)
All three roles use the same Hydra field set (RolloutSkipConfig /
RolloutTqSkipConfig / AsyncRolloutSkipConfig in verl/utils/skip/config.py). Defaults
live in verl/trainer/config/ppo_trainer.yaml under the respective skip.* key.
Parameters
enable (bool): Master switch for this role.
dump_dir (str): Root directory for cached shards (
~is expanded).steps (list[int]): Steps on which skip logic is eligible. Outside this list, the decorated function always runs normally.
For
skip.rollout: trainer global_steps (viaSkipManager.set_step).For
skip.rollout_tq: trainer **global_steps** (via ``SkipManager.set_step).For
skip.async_rollout: the feed-order index parsed fromsample_id(see section 5) — not trainerglobal_steps.
action (
cache|repeat):cache: If a valid dump exists for the current step, load it and skip generation; otherwise run generation and write under that step directory.
repeat: If any valid dump exists, load from a substitute step chosen by the algorithm below; otherwise run generation and dump as usual.
Note
Only cache and repeat are validated in config today, even though SkipAction in verl.utils.skip.base_skip lists additional enum values for future modules.
repeat step selection
rollout / async_rollout (RolloutSkip._find_latest_step)
When action=repeat and the current step directory is missing or incomplete:
If the directory for the current step is valid, use the current step.
Else use the largest available step strictly less than the current step.
Else use the smallest available step strictly greater than the current step.
If no valid dump exists, skip does not apply: the wrapped function runs and may dump afterward.
repeat does not guarantee the cached batch matches the current prompt or trainer step—use
it for debugging and iteration, and prefer cache when you need step-aligned replay.
rollout_tq (RolloutTqSkip._resolve_load_step_v1)
Same fallback strategy as above, but checks the V1-format cache file (tq_batch.pt, see on-disk layout below) instead of gen_batch.dp.
Hydra CLI examples
Colocated PPO (skip.rollout):
skip.rollout.enable=True
skip.rollout.dump_dir=/path/to/rollout_dump
skip.rollout.steps=[1,2,3,10]
skip.rollout.action=cache
TransferQueue-based V1 trainer (skip.rollout_tq):
skip.rollout_tq.enable=True
skip.rollout_tq.dump_dir=/path/to/rollout_dump
skip.rollout_tq.steps=[1,3,5]
skip.rollout_tq.action=cache
Fully async (skip.async_rollout):
skip.async_rollout.enable=True
skip.async_rollout.dump_dir=/path/to/rollout_dump
skip.async_rollout.steps=[1,2,3,4,5]
skip.async_rollout.action=cache
To pass a long step list from bash only (not valid inside static YAML):
skip.async_rollout.steps="[$(seq -s, 1 128)]"
On-disk layout
All roles share the same project-level directory structure; only the per-step files differ.
{dump_dir}/{experiment_name}_{project_name}/
└── GBS{gbs}_N{n}_in{prompt_len}_out{response_len}/
├── {step}/
│ ├── gen_batch.dp # rollout / async_rollout
│ ├── tq_batch.pt # rollout_tq
│ └── meta.json
└── ...
experiment_name / project_name: from
trainer.experiment_nameandtrainer.project_namein the run config.gbs, n, prompt_len, response_len: from
data.gen_batch_size(or train batch size),actor_rollout_ref.rollout.n,data.max_prompt_length, anddata.max_response_length.
Caches from colocated main_ppo (larger GBS) and fully async streaming (typically GBS=1) are generally not interchangeable unless these metadata match. rollout (gen_batch.dp) and rollout_tq (tq_batch.pt) use different file formats and are never interchangeable, even when the project metadata matches.
Role |
Cache file |
Contents |
|---|---|---|
rollout / async_rollout |
gen_batch.dp |
A DataProto saved via DataProto.save_to_disk — the full generate_sequences output (prompts, responses, log_probs, etc.). |
rollout_tq |
tq_batch.pt |
A torch.save payload containing: tensordict (all trajectory fields read from TQ via tq.kv_batch_get), tags (per-trajectory tag list), keys (trajectory-level TQ keys), global_steps (int). See section 4 for details. |
Minimal workflow (cache)
First run with
enable=True,action=cache, andstepslisting the steps you care about. Emptydump_dir→ generation runs and writesthe cache file+meta.jsonper step.Second run with the same config and compatible trainer metadata → listed steps load from disk instead of regenerating.
Partial caches (some step dirs missing): those steps regenerate on the next run; other steps still load if present.
Relationship to legacy RolloutSkip
If both skip.rollout.enable and legacy actor_rollout_ref.rollout.skip.enable are true,
SkipManager emits a DeprecationWarning and forces the legacy flag to False so only one
mechanism runs.
3. Rollout quick start (rollout role)
Use skip.rollout when training with main_ppo.py and trainer.use_v1=False
(RayPPOTrainer) and the standard AgentLoopManager.generate_sequences path. Configuration
fields and cache / repeat semantics are in section 2.
Wiring
RayPPOTrainer.fit() calls SkipManager.init(self.config) and SkipManager.set_step(self.global_steps) each training step.
AgentLoopManager.generate_sequences is decorated with @SkipManager.annotate(role=”rollout”).
The decorated function is a single entry point: it receives prompts, drives full-batch generation (chunk dispatch, concat, timing), and returns the complete DataProto. Skip logic wraps this unit as a whole — on cache-hit it returns the cached DataProto without invoking the LLM; on cache-miss it runs generation and dumps the result.
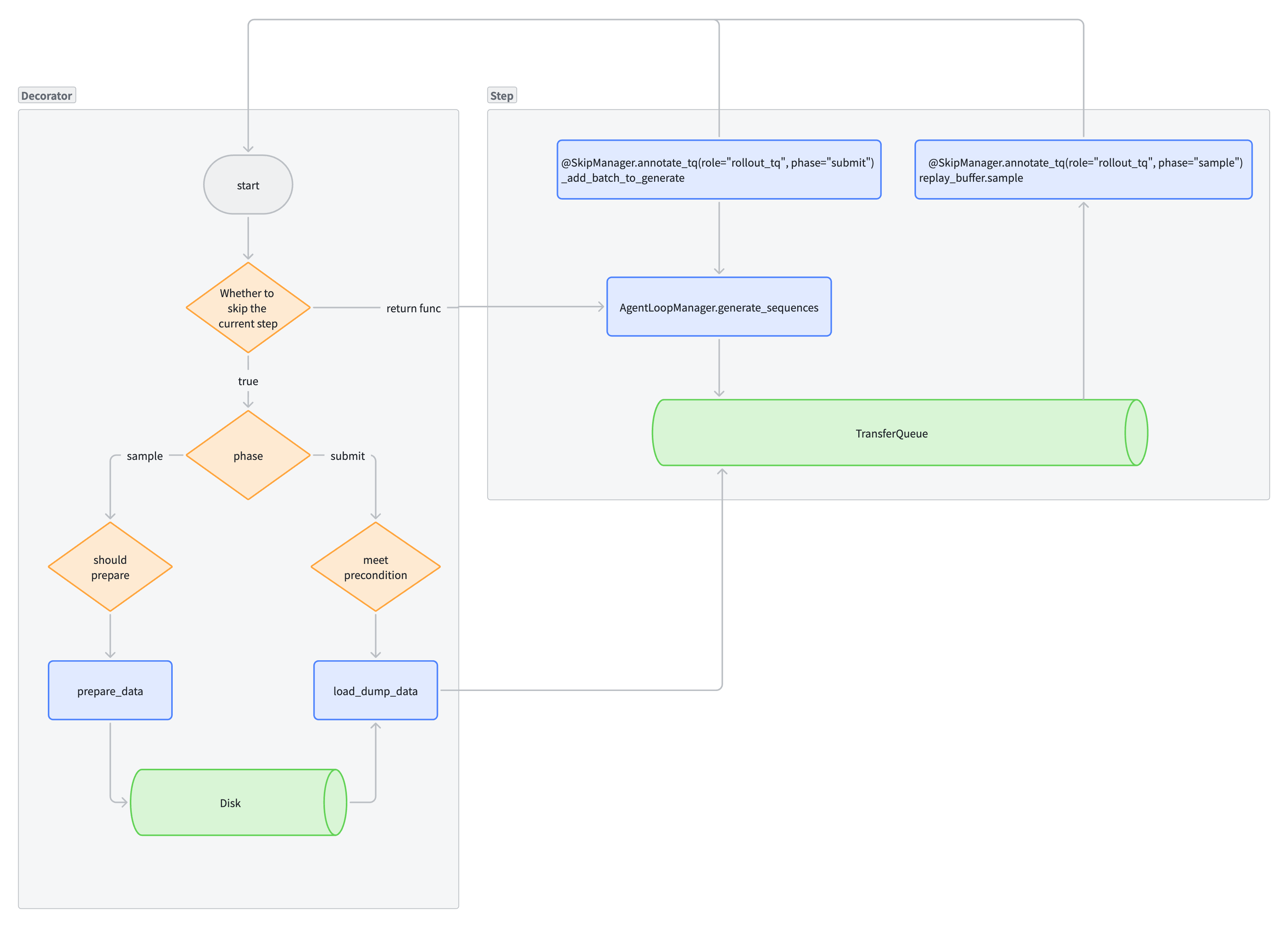
4. Trainer V1 quick start (rollout_tq role)
Use skip.rollout_tq when training with main_ppo.py and trainer.use_v1=True (V1 PPOTrainer + TransferQueue). This covers all V1 trainer modes: sync, colocate_async, and separate_async.
Important
Unlike rollout (section 3), the V1 TransferQueue path does not have a single generate_sequences entry point. Rollout is split across two methods that run at different points in the training step:
Submit phase — PPOTrainer._add_batch_to_generate: samples a batch from the dataloader, assigns uids, and dispatches prompts to the AgentLoopManager for generation.
Sample phase — ReplayBuffer.sample: waits for trajectories to finish, then collects them from TQ into a KVBatchMeta.
A single decorator cannot cover both because the cache-hit short-circuit must happen inside the submit phase — after uid generation (needed for key mapping) but before real rollout submission (which we want to skip). The solution is SkipManager.annotate_tq, a two-phase decorator selected by phase=”submit” or phase=”sample”.
Wiring
PPOTrainer.fit() calls SkipManager.init(self.config) and SkipManager.set_step(self.global_steps) each training step.
PPOTrainer._add_batch_to_generate is decorated with @SkipManager.annotate_tq(role=”rollout_tq”, phase=”submit”).
ReplayBuffer.sample is decorated with @SkipManager.annotate_tq(role=”rollout_tq”, phase=”sample”).
Method splitting
To give the submit-phase decorator a clean interception window, _add_batch_to_generate is split into two sub-methods:
@SkipManager.annotate_tq(role="rollout_tq", phase="submit")
def _add_batch_to_generate(self):
batch = self._next_train_batch() # dataloader + uid assignment
self._submit_batch_to_rollout(batch) # tag registration + generate_sequences
def _next_train_batch(self):
"""Advance the dataloader and return a batch with fresh uids."""
...
def _submit_batch_to_rollout(self, batch):
"""Register prompt tags in TransferQueue and dispatch to AgentLoopManager."""
...
When skip is disabled or the current step is outside skip.rollout_tq.steps, the decorator passes through and the function body runs normally (_next_train_batch then _submit_batch_to_rollout).
When skip is enabled and the step is eligible, the decorator takes over and the function body does not execute. Instead the decorator calls _next_train_batch itself (keeping the dataloader aligned even on cache-hit steps), then branches on cache availability.
Note
If future changes add logic between _next_train_batch and _submit_batch_to_rollout inside _add_batch_to_generate, that logic must also be reflected in the decorator’s submit-phase branch, since the decorator bypasses the function body when skip is active.
Two-phase flow
Phase 1 — cache-miss (first run, no tq_batch.pt on disk):
step()
|
+- _add_batch_to_generate() [submit decorator: skip enabled, cache-miss]
| +- _next_train_batch() -> batch with fresh uids
| +- maybe_load_and_inject() -> False (no cache)
| +- _submit_batch_to_rollout() -> real LLM generation dispatched to TQ
|
+- replay_buffer.sample() [sample decorator: skip enabled]
| +- (original sample runs) -> waits for trajectories, returns KVBatchMeta
| +- should_save() -> True (no cache, partition="train")
| +- prepare_data() -> kv_batch_get all fields -> torch.save -> tq_batch.pt
|
+- (downstream: reward, advantage, actor/critic update ...)
Phase 2 — cache-hit (subsequent run, tq_batch.pt exists):
step()
|
+- _add_batch_to_generate() [submit decorator: skip enabled, cache-hit]
| +- _next_train_batch() -> batch with fresh uids
| +- maybe_load_and_inject() -> True -> load_dump_data()
| | +- torch.load(tq_batch.pt) -> old keys, tags, tensordict
| | +- group old trajectories by uid prefix
| | +- map new uids -> cached groups (modulo cycling)
| | +- index_select_tensor_dict -> select/repeat trajectory rows
| | +- kv_batch_put trajectories with new keys + updated tags
| | +- kv_batch_put prompt-level keys with status="finished"
| +- return (skip _submit_batch_to_rollout -- no real LLM call)
|
+- replay_buffer.sample() [sample decorator: skip enabled]
| +- (original sample runs) -> finds finished prompts immediately, returns KVBatchMeta
| +- should_save() -> False (cache exists)
| +- (no prepare_data call)
|
+- (downstream: reward, advantage, actor/critic update ...)
On-disk format: tq_batch.pt
prepare_data saves a torch.save payload with four keys:
Key |
Contents |
|---|---|
|
A |
|
|
|
|
|
|
meta.json records {"global_steps": <int>, "num_trajectories": <int>} and is used by
_check_valid_v1_step_path for completeness validation.
Why kv_batch_get without select_fields?
KVBatchMeta from ReplayBuffer.sample holds only key/tag references — the trajectory data
body lives in TQ storage units. TQ clears keys at the end of each step (tq.kv_clear in
PPOTrainer.fit), so prepare_data must read the full data body before that cleanup.
Reading without select_fields ensures all downstream fields (reward, log-prob, masks) are
captured for a faithful replay.
Cache-hit injection: key remapping
load_dump_data cannot reuse old keys directly — new uids were just generated by
_next_train_batch. It remaps cached trajectories onto new uids:
Group by uid: Parse
old_keysand group trajectory indices bykey.split("_")[0]. Each group is one prompt GRPO group (usually n trajectories, but may be fewer if sessions failed).Map new uids to groups: For each new uid at position prompt_idx, select
groups[prompt_idx % num_cached_groups]. If cached groups are fewer than new prompts, groups cycle (modulo). If more, only the firstnum_promptsgroups are used.Fill *n* trajectories per prompt: For each session_id in [0, n), pick
group[session_id % len(group)]. If a group has fewer than n entries (partial failures), trajectories cycle within the group to fill the slot.Build new keys:
{new_uid}_{session_id}_0— matching the standard TQ key format.Update tags: Each trajectory tag’s
global_steps/min_global_steps/max_global_stepsare overwritten to the current step soReplayBuffer’s staleness check (_drop_max_off_policy_samples) does not discard them as off-policy. Theis_promptflag is removed from trajectory tags (it belongs only on prompt-level keys).Select tensor rows:
index_select_tensor_dict(data, traj_indices)picks (and possibly duplicates) rows from the cachedtensordict. This handles both regular tensors and NestedTensor (unbind -> select -> nested_tensor_from_tensor_list rebuild).Two ``kv_batch_put`` calls:
Trajectory data:
keys=new_keys,fields=new_fields,tags=new_tags— writes the actual trajectory content into TQ storage.Prompt-level markers:
keys=new_prompt_uids,tags=[{"is_prompt": True, "status": "finished", ...}]— marks each new prompt as finished soReplayBuffer.sample’s_has_enough_samplespasses immediately without polling.
After injection, TQ holds the same structure as a normal completed rollout: n trajectory keys
per prompt plus one prompt-level key with status="finished". replay_buffer.sample picks
them up on the next call and returns a KVBatchMeta whose data is the injected cache.
5. Fully async quick start (async_rollout role)
In advance/fully_async, Trainer and Rollouter run in separate processes. Rollout generation
happens on the Rollouter via streaming single-sample dispatch. Use skip.async_rollout (not
skip.rollout) when launching fully_async_main. Shared Hydra fields and on-disk layout are
in section 2.
Important
In async_rollout, a step is not the trainer timeline. It is only the prompt request /
feed order on the Rollouter: the monotonic index in sample_{epoch}_{index} when
FullyAsyncRollouter enqueues the next prompt. Under concurrent rollout, completion order can
differ from feed order; do not treat these indices as trainer global_steps or parameter-sync
boundaries when configuring skip.async_rollout.steps.
Step key from sample_id
Each fed sample carries an id of the form sample_{epoch}_{index} (for example
sample_0_42). The integer matched against skip.async_rollout.steps and used for on-disk
directories is the last segment — Rollouter feed-order index at enqueue time.
Wiring
FullyAsyncRolloutercallsSkipManager.init(self.config)in the Rollouter process.FullyAsyncAgentLoopManager.generate_sequences_singleis decorated with@SkipManager.annotate(role="async_rollout")and receivessample_idfor online step resolution.
6. Design and implementation
SkipManager API
SkipManager (verl.utils.skip.skip_manager) is a class-level registry:
``init(config)``: Parse
config.skipintoSkipManagerConfig, instantiate one skip module per registered role, and store them inSkipManager.skip_instances.``set_step(step: int)``: Set
SkipManager.stepfor roles withsupport_online_step = False(trainerglobal_stepsinmain_ppoand V1PPOTrainer).``annotate(role, **kwargs)``: Decorator factory for sync or async functions (used by
rolloutandasync_rollout).``annotate_tq(role, phase)``: Two-phase decorator factory for the V1 TransferQueue path (used by
rollout_tq). See section 4.
Decorator flow: annotate (rollout / async_rollout)
call decorated function
│
▼
skip disabled or role missing? ──yes──► run original function
│no
▼
resolve step (set_step vs extract_step)
│
▼
step ∉ config.steps? ──yes──► run original function
│no
▼
meet_precondition (cache/repeat)? ──yes──► warp_function (load cache)
│no
▼
run original function → prepare_data (dump)
Decorator flow: annotate (rollout_tq)
BaseSkip interface
Each skip module subclasses BaseSkip (verl.utils.skip.base_skip) and registers via
@register_skip("role_name").
``support_actions``: Allowed
SkipActionvalues for this module.``support_online_step``: When
True, useextract_stepper call instead ofSkipManager.step.
Instance methods: is_enabled, meet_precondition, warp_function, prepare_data, and
extract_step (required when support_online_step is True).
RolloutSkip / RolloutTqSkip / AsyncRolloutSkip (verl.utils.skip.rollout_skip)
implement generation caching for the three roles. RolloutTqSkip extends RolloutSkip and
adds V1-specific methods: should_save, maybe_load_and_inject, load_dump_data,
has_v1_cache, _resolve_load_step_v1.
Intercepted functions
Role |
Decorated function |
Defined in |
Step source |
|---|---|---|---|
|
|
|
|
|
PPOTrainer._add_batch_to_generate (phase=”submit”) |
verl/trainer/ppo/v1/trainer_base.py |
SkipManager.set_step -> trainer global_steps |
|
ReplayBuffer.sample (phase=”sample”) |
verl/trainer/ppo/v1/replay_buffer.py |
SkipManager.set_step -> trainer |
|
|
|
|
``rollout`` wraps the full batch Agent Loop RPC (chunk dispatch, concat, timing) as one skip unit.
``rollout_tq`` wraps two methods with a single annotate_tq decorator, selected by
phase. The submit phase intercepts before real generation; the sample phase intercepts
after sampling to persist results.
``async_rollout`` wraps one streaming sample’s generate_sequences_single(self, prompts,
sample_id) so concurrent samples resolve step independently.
Step resolution: set_step vs support_online_step
See section 2 for steps semantics per role.
Shared ``SkipManager.step``: One class-level slot per process. Fits sequential trainer loops (
main_ppo):set_step(global_steps)before rollout.Online step:
AsyncRolloutSkipsetssupport_online_step = Trueand parsessample_idon each call so in-flight async samples do not share a single counter. Forrepeat,RolloutSkiprecomputes_find_latest_stepon everymeet_preconditionandwarp_functioncall (no shared mutable step field on the skip instance).
Extending with custom skip modules
Subclass
BaseSkipfromverl.utils.skip.base_skip.Decorate the class with
@register_skip("your_role_name").Add a matching field under
SkipManagerConfig.Attach
@SkipManager.annotate(role="your_role_name"). For concurrent pipelines, prefersupport_online_step = Trueand pass step identity through call arguments.For split-architecture paths (like V1’s submit/sample separation), use @SkipManager.annotate_tq(role=…, phase=…) and split the target method so the decorator can intercept between the two sub-steps.